基于多重索引的时序数据检索方案
背景:
在股票量化交易系统中,包括股票交易,行情监控,和回测系统,通常对股票行情数据的获取时间要求和数据压缩率非常高,特别是细化到分钟级,秒级,毫秒级的数据查询上,在数据量大的情况下,通常的检索方式会非常耗时,占用内存也非常大。基于这种情况下,本文提出了一种基于底层数据结构numpy建立多重索引的内存占用率低,查询效率高的时序数据检索方案。
现状:
现有的时序数据,以股票行情为例,基本上是根据numpy和pandas进行行情数据查询。数据存储方式根据不同的检索需要会以不同的方式存储,常见的有以csv,bcolz,hdf5等格式存储于磁盘,或者以ES(elasticsearch),influxdb等时序数据库。不同的存储方案的有着各自不同的优缺点。 以csv等文件存储,优点是数据格式简单,方便查看,缺点是数据无压缩,占用空间大。 以bcolz,hdf5等方式存储,优点是数据经过压缩,占用空间小,查询方便,支持条件语句查询。缺点是存储方式为磁盘存储,查询速度慢。 以ES等方式存储,优点是数据存放内存,查询速度快,缺点是数据未压缩,占用内存大,而内存成本要比磁盘高很多,提高了系统的成本。
目的:
本方案主要解决的是时序数据在存储和查询的过程中,比现有的常见方案,节省更多的内存占用,提升更快的查询速度。
实现:
设计原理:
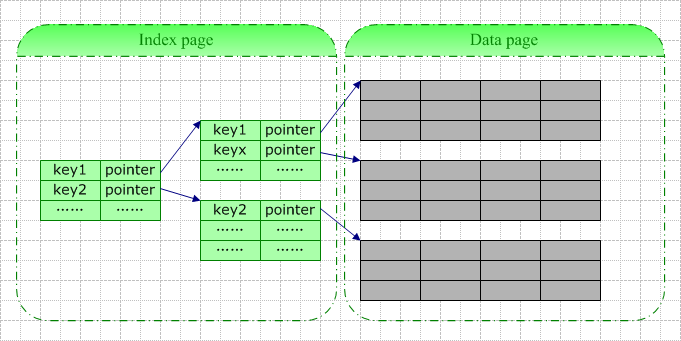
建立多重索引,每支股票每天的数据以时间建立一个索引,每支股票所有的历史数据再建立一个索引。
数据格式:
用bcolz作为存储格式。bcolz是目前做量化系统常用的压缩格式,压缩比率较高。
具体实现
将所有股票数据存放在 data (ctable)里面。
index(ctable)每条记录,用来记录某个股票某一天在data中的起止位置。
index的attrs中记录某个股票有哪些天的历史数据。构成二级索引。
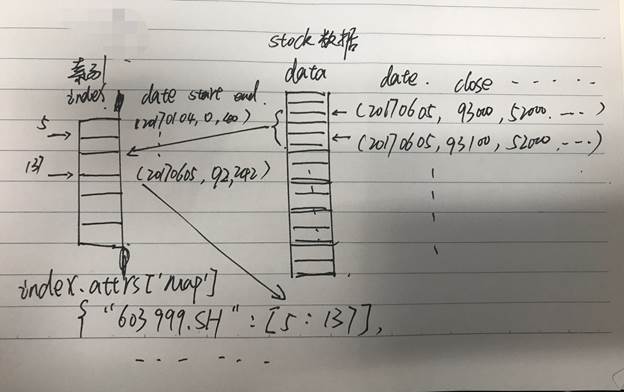
步骤1. 将索引数据加载到磁盘,记为index。
步骤2. 从index中获取属性“map”,获得所有股票在index中的存储位置,记为map。
步骤3. 根据map和参数股票代码(code),日期(date),查找出对应的查询数据在股票原始数据(data)中所在的位置,记为range1。
步骤4. 打开股票原始数据(data),根据索引位置range1,直接获取对应数据。
增量更新
数据(data): 每日新增数据 定时增量追加 到原来的data上。 索引(index): 读取旧索引(index), 将data中新增的数据位置插入旧索引尾部,重新生成新索引(index)。
数据修改
数据(data): 根据索引(index),返回记录在data中的位置,直接修改data(ctable)中的数据。
索引: 正常记录的条数不变,只是内容更改,索引无需更新。
数据校验:
每次数据更新(包括增量更新和修改),都会生成(更新日期,数据md5,索引内容md5,更新方式,数据条数,索引条数)的日志,
通过监控所有机器的日志进行校验数据的一致性。
数据回滚方案
1.定期备份全量数据/索引 文件。
2.全量更新出错,则重新执行全量更新
3.增量更新出错,则回滚到备份的全量数据,重新更新。
4.某台机器更新出错,则从其它同步正确的机器同步一份过来。
6.性能: 初步实现查找的功能。未优化的情况下,初步测试:
count: 21563
time: 231.19000000000003
21563次查询,耗时231s,平均耗时 10.7ms/次
ps:查询数据:100只股票20150601到20170630之间,按天查询。(模拟 get_bar 接口)
数据校验:
如何验证数据同步的正确性,还有同步出错时,数据的回滚和重新生成。 更新包的数据校验(从数据长度+md5?)
注意点:
通过对第一版的结论进行分析,发现本地化后性能没有提升的原因的瓶颈出现在数据转换上。 numpy转换为原先的TradeData时,数据的重新赋值和将数字格式的date,time转换为python的datetime格式耗时巨大。
优化:
通过优化datetime的转换函数,和重构TradeData数据结构,减少numpy转换TradeDate时的赋值成员个数。使得效果大大提升。 同时,本地话的好处是减少网络的影响。特别是客户端的版本,对待全部股票扫描的策略, 本地windows机器上跑的时候网络较差,这块本地化的优势比较明显。